Rendering Path (一) 簡介
渲染路徑簡介
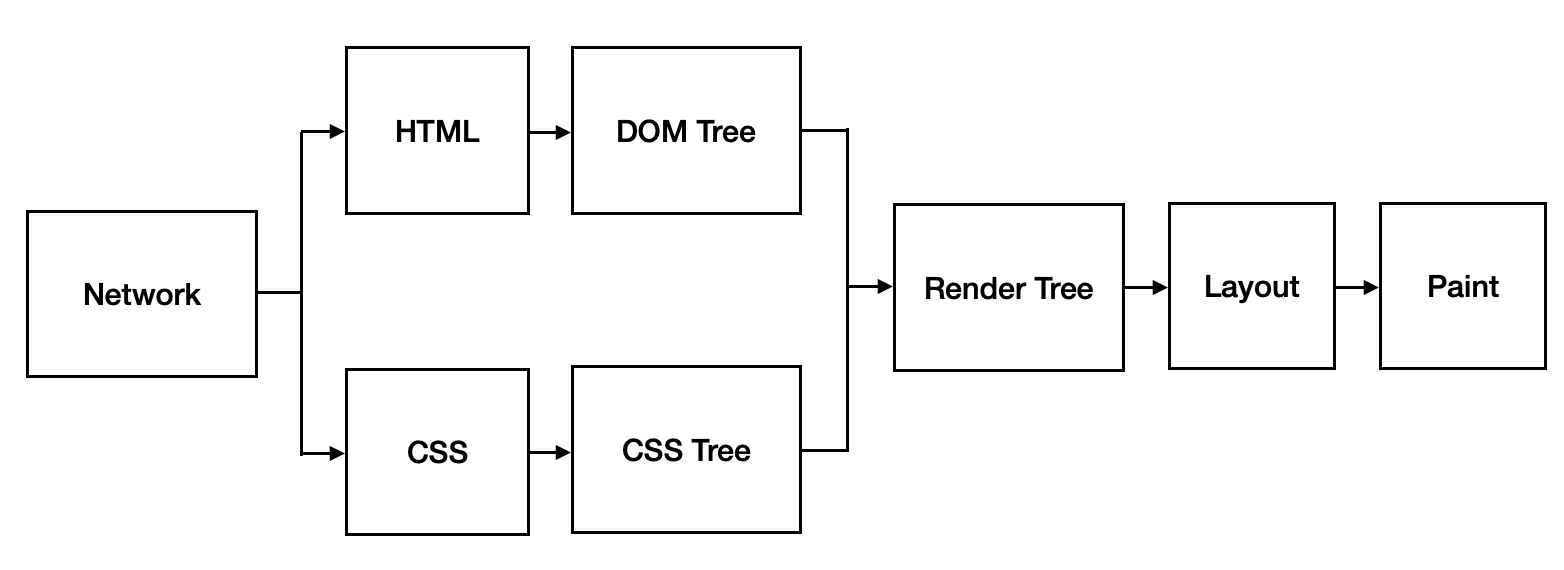
Rendering Path 是瀏覽器如何將網頁檔案轉化成網頁的處理路徑,其路徑包含了網路(Network)、HTML、CSS檔案轉化成兩顆獨立樹狀結構、兩顆樹狀結構合併成渲染樹(Render Tree)、版面配置(Layout)、繪製(Paint),每個路徑之間關係會如同下圖所示那樣,首先會先從網路找到提供網頁的伺服器獲取對應網頁(由HTML、CSS)、當客戶端的瀏覽器一拿到這些檔案,便會將他們轉化為名為 DOM Tree 和 CSSOM Tree,接著再將兩顆樹合併成渲染樹,接著根據渲染樹和DOM Tree來計算網頁上的每個元件的實際擺放位置以及大小,最後再用瀏覽器的繪製方法來完整呈現每一個元件的真實面貌,比如輪廓、顏色之類的。在本文會談論到路徑上會包含到的東西,但比較偏重於Network至Layout之間的東西,剩下將由後續的文章進行補充,因此而將本文歸類為(一)。
網路
當使用者開始透過URL來瀏覽網頁時,瀏覽器會先試著解析URL對應的IP是誰,唯有知道IP是哪個伺服器負責提供對應的網頁服務才能進行網頁的相關處理以及向誰發送”要求網頁檔案回傳過來”的請求。
而解析URL的流程主要流程為:
- 檢查瀏覽器本身的快取(Cache)是否有URL的對應IP,若沒有則繼續朝下一個目標找
- 檢查(執行目前的瀏覽器)作業系統的快取(Cache)是否有URL的對應IP,若沒有則繼續朝下一個目標
- 檢查離本地端較近的路由器(Router)是否有URL的對應IP,沒有朝下一個目標找
- 對ISP發送請求詢問它那邊的快取是否有對應IP,沒有朝下一個目標找
- 就開始針對ISP的DNS Server進行遞迴式搜查,直到找到對應IP

不論流程會如何處理,最後結果只會有對應的IP和不存在對應IP的訊息,在這裡只探討前者,當瀏覽器已經得知對應IP是什麼,那麼使用者(瀏覽器)會再重新對該IP來要求伺服器回傳網頁的對應檔(包含了HTML檔案、CSS檔案、JavaScript檔案)給使用者的瀏覽器,而回傳檔案的形式並不會一口氣以一個完整檔案傳過去,而是以固定大小的封包(Packet)形式將原檔案切分成好幾等分傳給使用者的瀏覽器來處理。
HTML 轉化成 DOM Tree
當瀏覽器收到HTML檔案被切分出來的封包時,瀏覽器不會直接等待完整檔案被拼湊出來,而是邊收邊將收到的內容按照DOM形式來建立一個DOM節點,每一個節點都各代表一個獨立的內容或者對應標籤,當一個節點A對應原HTML檔案的標籤或者內容是在另一個節點B對應的標籤內部的話,那麼這個節點A會根據內部的深度來決定是否為節點B的子節點(Child Node)?還是為節點B的後代節點(Descendant Node),比如說節點A對應的標籤是elementA,而節點B的標籤是elementB,若elementA還被其他元素包含著,那麼節點A就會是節點B的後代節點
1 | <elementB> |
但若elementA沒被其他元素包含著,那麼節點A就會是節點B的子節點
1 | <elementB> |
最後由這些節點的生成以及如何連接來構成一個樹狀結構,該樹狀結構被稱之為DOM Tree,在這個樹狀結構中會有代表HTML標籤(元件)的元素節點、代表其元件屬性的屬性節點、代表一般文字內容的文字節點以及代表註解內容的註解節點等。
拿下面的HTML程式碼來當例子的話:
1 | <html> |
在解析的過程中,會被轉化為以下樹狀結構,首先html標籤會先被瀏覽器擷取來建立一個獨立的DOM節點,接著再讀取到head標籤時,由於它是位於html標籤內部且沒其他標籤包含著,所以它會被設定成html標籤對應節點的子節點並且被html對應節點連接著,而link對應節點會因為這樣被設定成head標籤對應節點的子節點,而後body、h1、p、label也皆因為這樣而與其他節點進行連接,最後形成以下結果: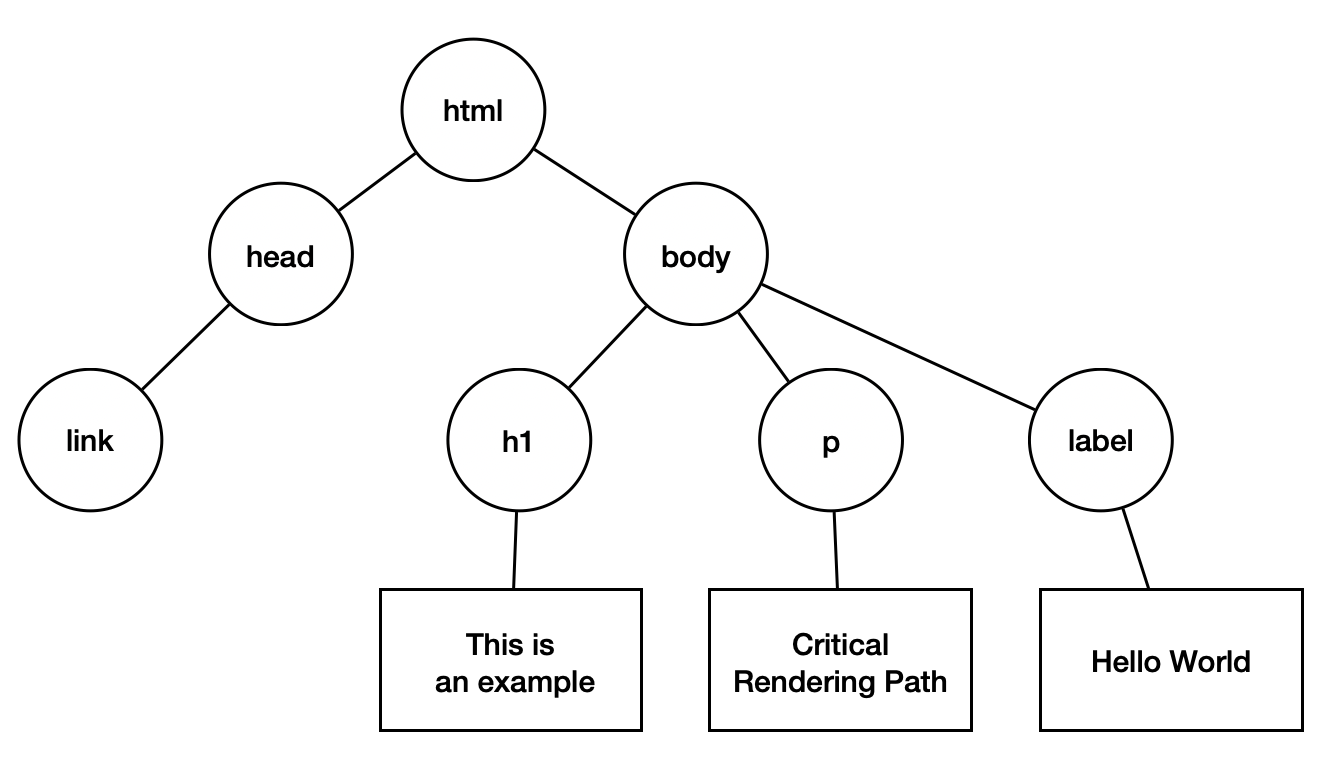
CSS 轉化成 CSSOM Tree
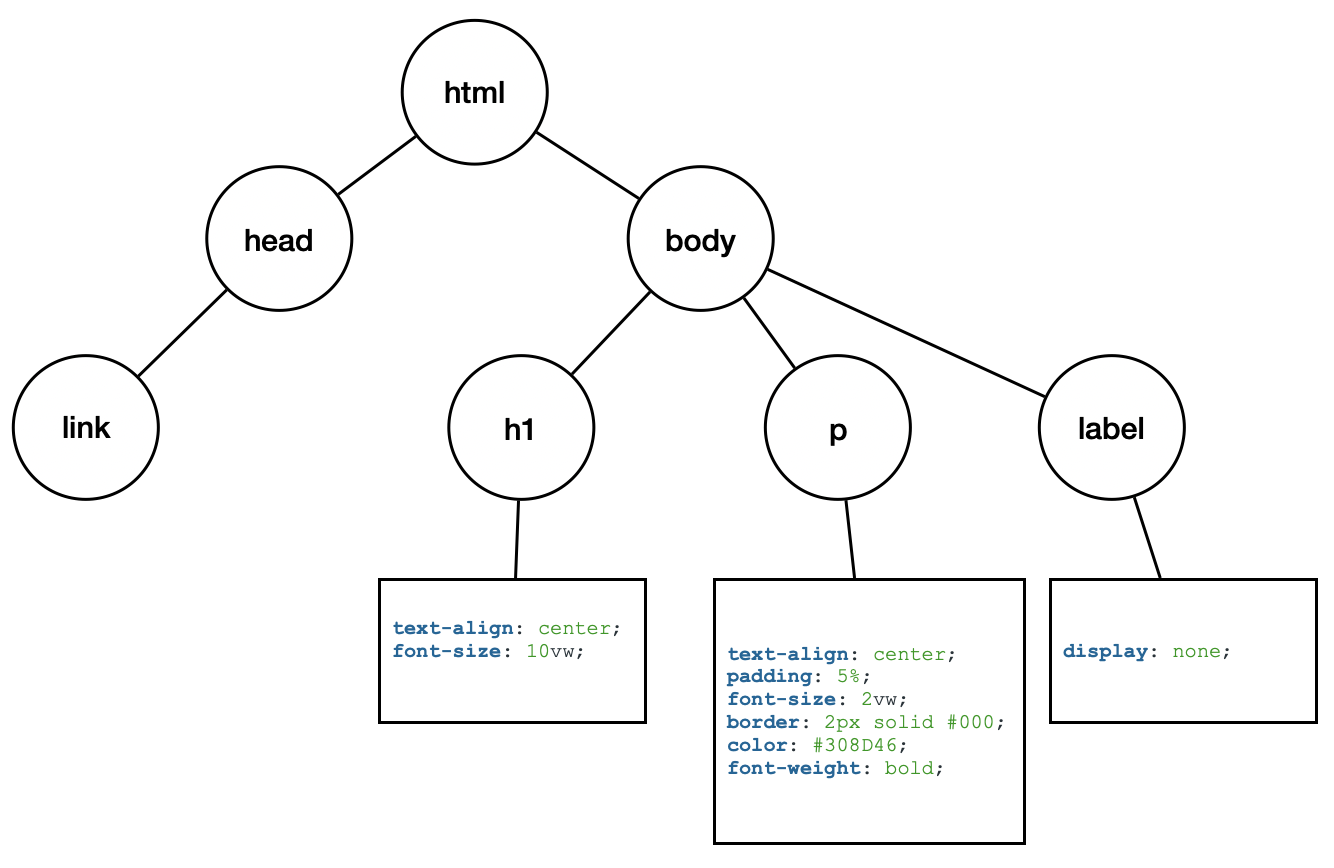
當瀏覽器收到CSS檔案被切分出來的封包時,瀏覽器會直接等待整個CSS檔案拼湊出來才開始解析,這是因為CSS屬性很容易被後續接收到的內容給覆蓋掉,甚至造成結構性的改變,所以必須等待封包組裝成一份完整的CSS檔案才開始解析,當開始解析時,由於 HTML 轉化成 DOM Tree 的過程很有可能因為邊接收邊處理而有初步產生的 DOM Tree,根據樹狀結構再將樣式表對應的標籤與樹狀結構中對應標籤的節點進行綁定,也就是說在CSSOM Tree會以DOM Tree為雛形,並且再將對應的樣式附加至每個對應元件的節點,而這個樹狀結構被稱之為CSSOM,在這樹狀結構中,只會出現代表HTML元件的元素節點。
若以上面為例子來建立特定CSS樣式的話,其內容會是
1 | p { |
產生DOM之後的JavaScript
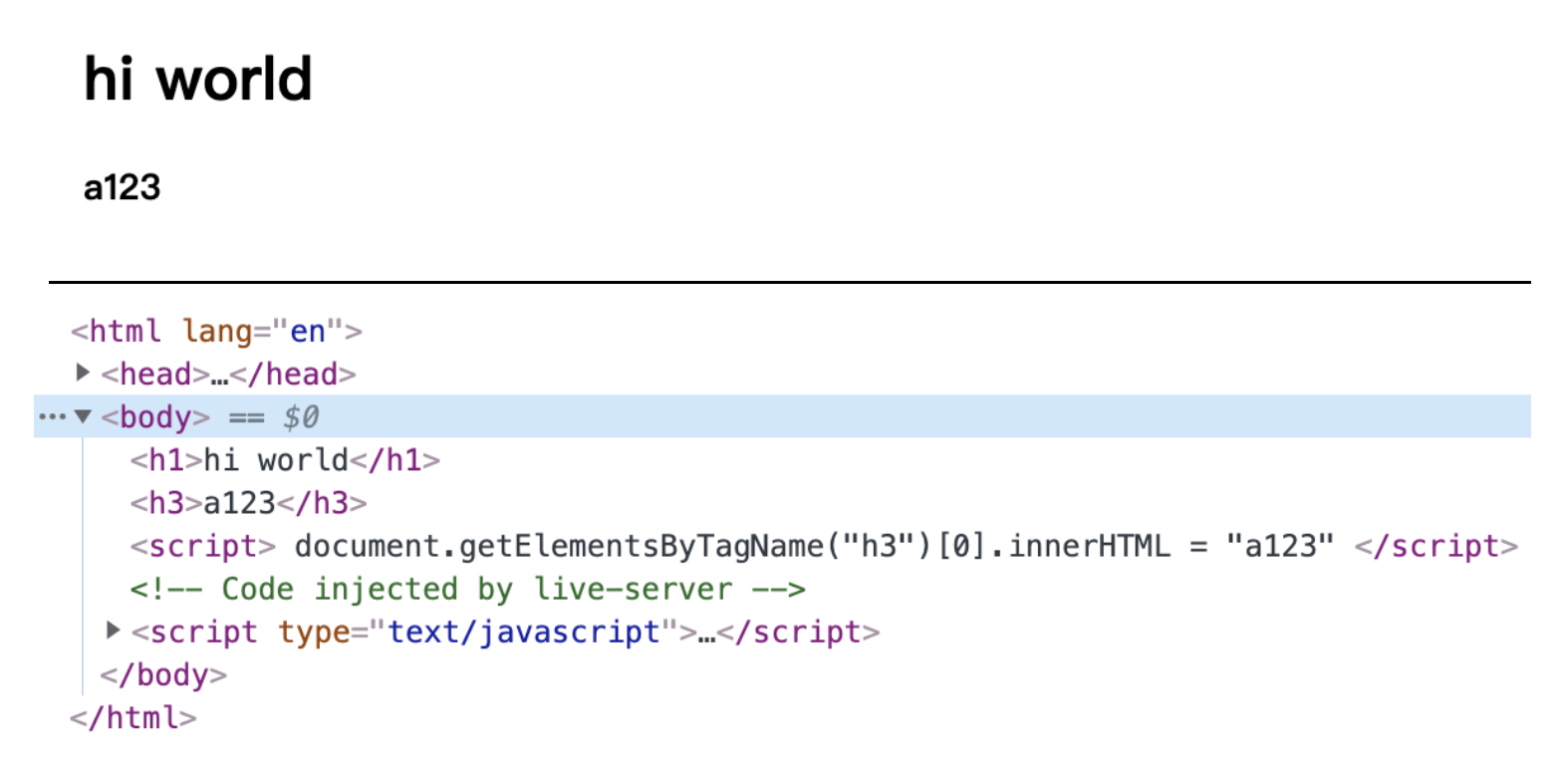
在產生DOM和CSSOM之後,我們還可以透過JavaScript在Render Tree產生之前來變更DOM或者CSSOM的內容,假設一個HTML檔案內容為以下內容,後頭有個script包覆著的內容,其內容會是JavaScript的語法。
1 | <!DOCTYPE html> |
而其內容是變更原本沒內容的h3標籤元素:在這裡你可以看到內容會被指定為”a123”。
1 | document.getElementsByTagName("h3")[0].innerHTML = "a123" |
而當我們以瀏覽器來讀取整份檔案時,會在DOM Tree裡發現h3標籤元素所儲存的內容變更為”a123”,不再是無內容,從這邊展現出JavaScript可以在合併前影響著DOM和CSSOM
若script部分程式碼是擺在h3元素定義之前的話,其script執行的結果會是無法改變h3元素內容。
渲染樹
在經過解析後從而獲得DOM以及CSSOM之後,接著會根據兩者對應的元件是否一樣來進行同元件在DOM和CSSOM的節點合併,合併後的節點會以DOM節點的形式多增加一個子節點(如同下圖紅框中的節點)來表示父節點(網頁元素)要調整的樣式是為何。
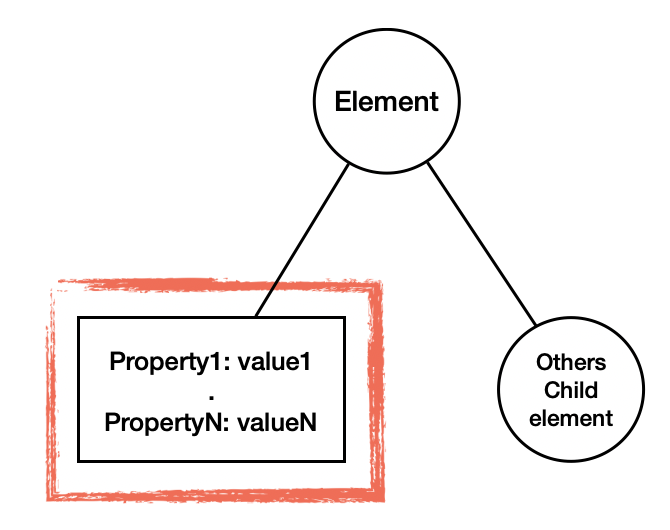
另外會根據該元素是否能夠正常在瀏覽器顯示來決定該元素是否存在於Render Tree,也就是說當元素本身設定為display: none的屬性時,該元素不會在這個階段挑選為合併後的結果,預設上有這設定的元素有html、head、link、body等元素,所以在合併結果上並不會看到它們。
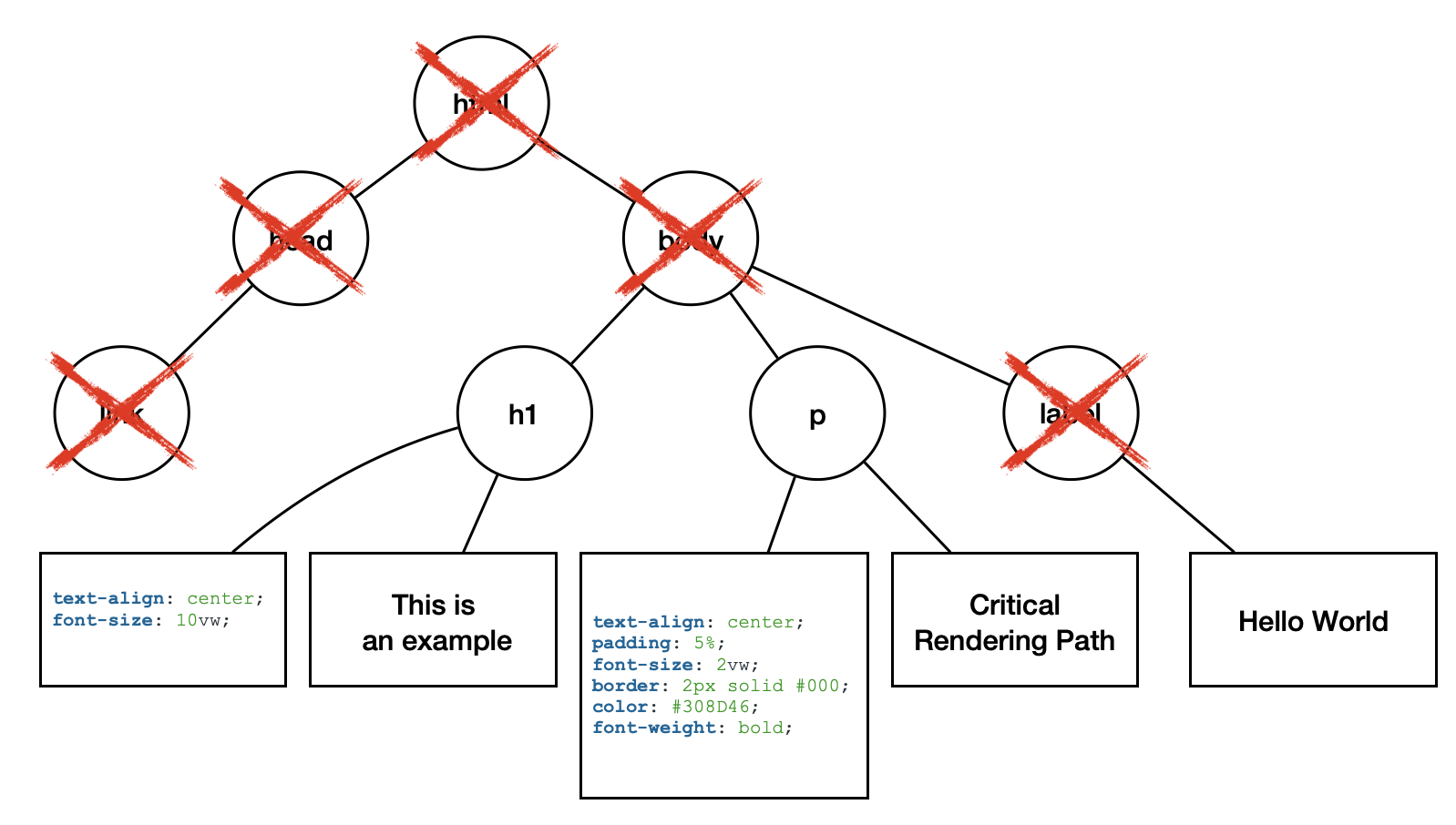
我們繼續拿DOM和CSS提到的例子來為他們合併成一個Render Tree,在這裡你可以看到叉叉,而它表示著其元素本身是display: none的元素,所以無法成為最終合併後的結果,另外也由於body元素也被跟著剔除,所以會在最終結果上替合併後的新樹添加新的root元素,而在那下的每個節點都會有新加進來的屬性節點,這些節點會在後續paint程序為父節點增添樣式。
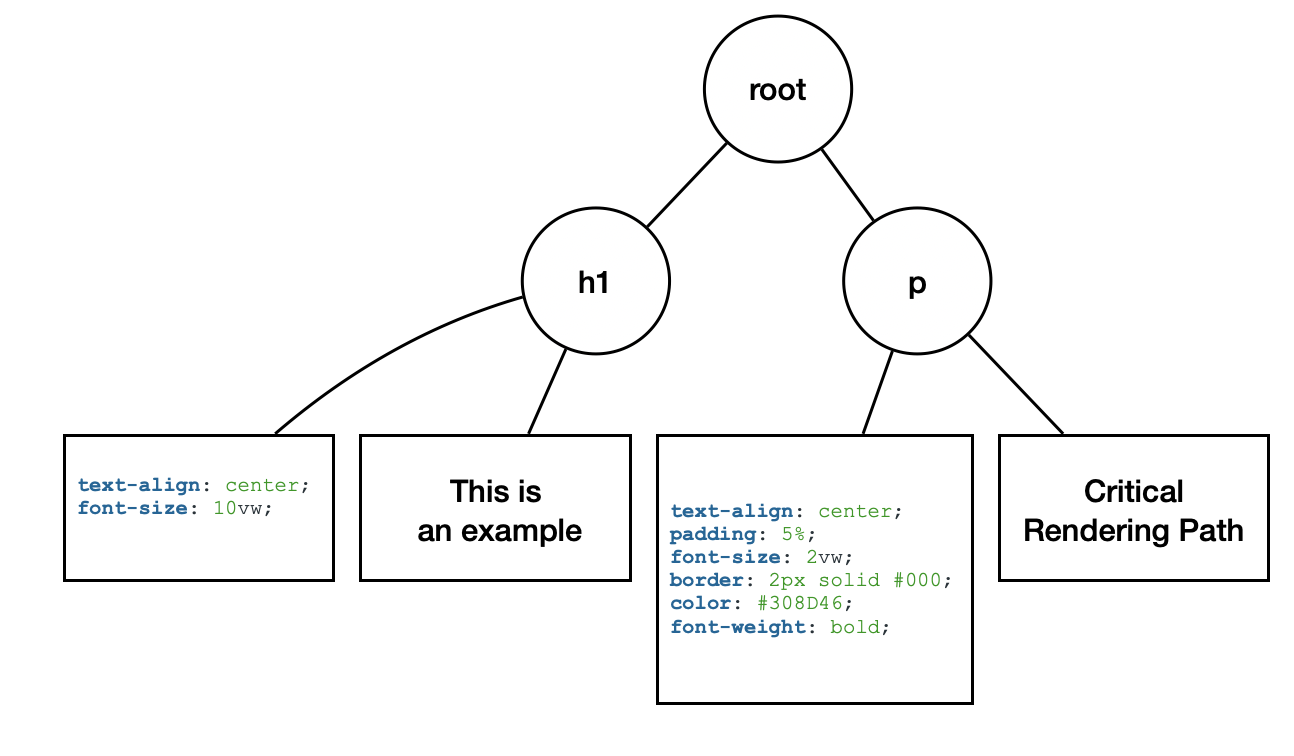
最後的合併結果會是:
版面配置和繪製
在版面配置中會利用前面階段獲取的樹狀結構來計算網頁元件實際會在頁面上擺放的位置、大小以及如何擺放,計算完之後便會跳到下一個階段-繪製,繪製過程會開始依據渲染樹指定的樣式來對頁面上的pixel來呈現每個元件的真實面貌,比如背景顏色、背景圖片、邊框、輪廓等等,過程中會遍歷著渲染樹並對著指定元件在特定螢幕位置進行無數次(由render/瀏覽器所提供)paint的呼叫來實際達成元件的呈現。
Reference
本Blog上的所有文章除特别聲明外,均採用 CC BY-SA 4.0 協議 ,轉載請註明出處!